Postgres, Knex Transactions and Async Hooks
Initial Idea
Knex is one of the most popular Query builders for NodeJS. This can be attributed to its:
- ease of use
- highly customizable and modular architecture
- great documentation
However, whenever I used knex, I always experienced a minor inconvenience when handling knex transactions.
In order to create a transaction you have to issue the following command:
await knex.transaction(async trx => {
// do stuff with trx here
// ...
})or without using a callback
const trx = await knex.transaction()
// do stuff with trx here
// ...
await trx.commit();
// or trx.rollback();The problem emerges when attempting to pass the trx object into other functions. I frequently saw code like this in several firms that used knex:
const trx = await knex.transaction()
await foo1(arg1, arg2, trx);
await foo2(arg3, arg4, trx);
await trx.commit();
...
// some other file
function foo1(arg1, arg2, trx) {
return (trx || knex).update(/*...*/).where(/*...*/)
}
function foo2(arg1, arg2, trx) {
return (trx || knex).select(/*...*/).from(/*...*/)
}This implies you’d have to send the trx object along to any other functions that could use it. To complicate matters further, it was desirable in some circumstances to default to the knex query builder whenever a transaction object was not supplied, therefore the code had to include the vexing (trx || knex) phrase in every single place where a query would be conducted.
I ideally intended to build a block of code by calling two functions: startTransaction and endTransaction. Every query conducted inside this scope would have to be a part of the created transaction.
await knex.startTransaction()
await foo1(arg1, arg2);
await foo2(arg3, arg4);
await knex.endTransaction()
...
// some other file
function foo1(arg1, arg2, trx) {
// will use a transaction if it exists
// or it will use the default knex instance
return knex.update(/*...*/).where(/*...*/)
}
function foo2(arg1, arg2, trx) {
// will use a transaction if it exists
// or it will use the default knex instance
return knex.select(/*...*/).from(/*...*/)
}Naive Implementation
The first naive approach would simply be to manually invoke a transaction by using knex.raw.
await knex.raw("BEGIN;");
await foo1(arg1, arg2);
await foo2(arg3, arg4);
await knex.raw("COMMIT;");
...
// some other file
function foo1(arg1, arg2, trx) {
// will use a transaction if it exists
// or it will use the default knex instance
return knex.update(/*...*/).where(/*...*/)
}
function foo2(arg1, arg2, trx) {
// will use a transaction if it exists
// or it will use the default knex instance
return knex.select(/*...*/).from(/*...*/)
}This would have worked perfectly well if the system simply handled one request at a time. In knex, by chaining commands to the transaction object we manage to associate those commands with this transaction. A “Begin” command executed with knex.raw would start a transaction throughout the whole connection, implying that a second request might be made in the same context. This would result in an error (“WARNING: there is already a transaction in progress”).
To resolve this issue, it appears that we will have to revert to the previous method of utilizing the transaction object within the query. A far better idea would be to create a transaction object when issuing the startTransaction command and store it into the context storage of the request that triggered it. Whenever a query is executed, it would check this storage in order to find out if such a transaction exists and is active. If not, it would try to use the default knex instance to resolve the query. However, there is a problem: NodeJS is singlethreaded and therefore does not retain a context per request.
Enter Async Hooks
Version 8 of NodeJS introduced an experimental version of Async Hooks. The module helps you monitor various “Asynchronous Resources” in the Node Ecosystem which represent objects with associated callbacks (for example Promises, Timers, etc). In general, the async resources have three states:
- Creation
- Callback execution
- Destruction
An Async Resource may generate additional resources over its lifespan. Every resource contains an Async ID that uniquely identifies it, as well as a Trigger ID which is practically the Async ID of the resource that spawned it.
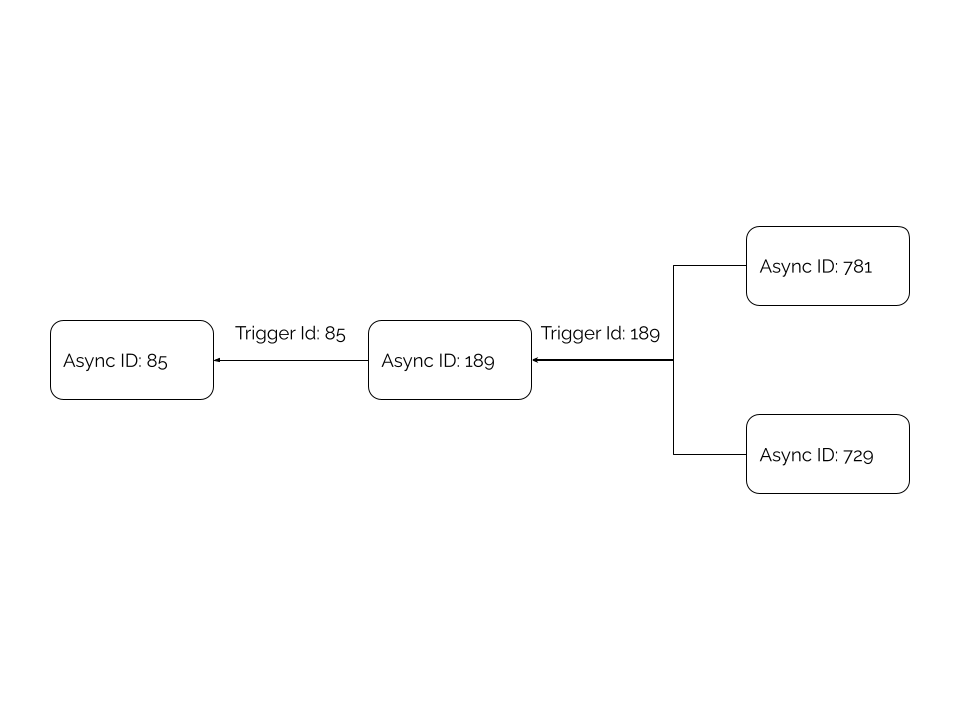
We may construct local storage for distinct async resources that share the same parent by associating them together. Fortunately, the AsyncLocalStorage module in the async-hooks package allows us to construct a shared context across such resources.
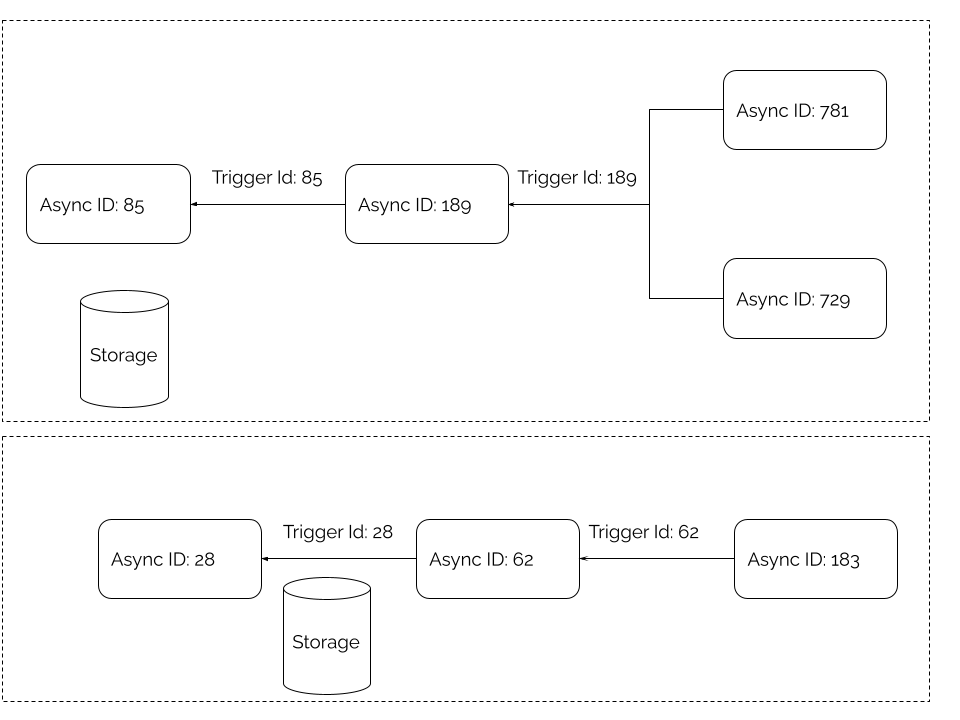
The following code snippet adds a middleware to an ExpressJS server which creates a unique local storage for every request.
const { AsyncLocalStorage } = require("async_hooks");
const asyncLocalStorage = new AsyncLocalStorage();
app.use((req, res, next) => {
const localStorage = new Map();
asyncLocalStorage.run(localStorage, () => {
next();
});
});From that point onwards every function called in that asynchronous storage (all asynchronous resources sharing the same parent id), will have access to this same instance of the localStorage variable.
const { AsyncLocalStorage } = require("async_hooks");
app.get("/", (req, res) => {
asyncLocalStorage.getStore().set("demo", 42);
const result = await new Promise(
// the promise will be resolved with the results from
// function fa after 1 second
(resolve) => setTimeout(() => resolve(fa()), 1000)
);
// the result will be 42
res.send(result);
});
});
fa() {
// access the async local storage for this async id
return asyncLocalStorage.getStore().get("demo");
}We finally have found a way to overcome the lack of a local storage per request. The next task would be to create the “startTransaction” and “endTransaction” functionality.
The Context Handler
By utilizing async hooks we can now create the Context Handler: a module useful for monitoring and editing context storage. Each entry in the storage has its own format (kept simple for now):
class ContextStoreEntry {
constructor(data) {
this._created = new Date().getTime();
this.data = data;
}
getData() {
return this.data;
}
}The next step was creating the Context Handler class (could use dependency injection to refer to the same instance everywhere or simply be a singleton).
class ContextHandler {
constructor(ns) {
// The cls is used here to provide
// a constanst storage throughout the lifetime of a request
this.cls = new AsyncLocalStorage();
this.db = null;
}
/* Checks if db is initialized */
_dbInitialized() {
if (!this.db) {
throw new Error(
"Database could not be initialized"
);
}
}
/* To be used by express to initialize the scope */
getMiddleware() {
/* Middleware registering api request's trace */
return (req, res, next) => {
// generate a unique uuid for the trace
const localStorage = new Map();
return asyncLocalStorage.run(localStorage, () => {
const traceId = uuidv4();
localStorage.set("traceId", traceId);
localStorage.set("store", new Map());
return next();
});
};
}
/* Checks if the current context for the session has been setup */
_checkInitialized(throwError) {
const traceId = this.cls.getStore().get("traceId");
if (!traceId && throwError) {
throw new Error(
"Could not setup context for session"
);
}
return traceId;
}
/* Sets data for the context store */
store(key, data) {
this._checkInitialized(true);
const store = this.cls.getStore().get("store");
store.set(key, new ContextStoreEntry(data));
}
/* Gets data stored in the context by key */
getFromStore(key) {
if (!this._checkInitialized()) return null;
const store = this.cls.getStore().get("store");
if (
key in store
&& store.get(key) instanceof ContextStoreEntry
) {
return store.get(key).getData();
}
return null;
}
...
}
// singleton
module.exports = new ContextHandler();The getMiddleware function should be called during ExpressJS setup so that it can initialize a local context for each request. In the code presented above, we’ve already created a very simple storage strategy for each request; that feature is pretty useful on its own, but we’ll go even further. Next in line is the addition of the startTransaction and endTransaction methods:
class ContextHandler {
...
/* Initializes a knex transaction scope */
async startTransaction() {
this._dbInitialized();
const oldTrx = this.getFromStore("trx");
let trxCount = this.getFromStore("transactionCount");
// if an older transaction exists simply increase the
// transaction count
// NOTE: Postgres SAVEPOINTs are not handled here.
// Maybe in a future iteration
if (!trxCount) trxCount = 0;
trxCount++;
this.store("transactionCount", trxCount);
// if the transaction count > 0 then there
// already is a transaction so just leave
if (oldTrx) return;
const trx = await this.db.transaction();
this.store("trx", trx);
}
/* Clears existing transaction */
_clearTransaction() {
this.clearFromStore("trx");
this.clearFromStore("transactionCount");
}
/* Commits the transaction */
async endTransaction() {
this._dbInitialized();
const trx = this.getFromStore("trx");
if (!trx) {
throw new Error(
"Could not find transaction to finish"
);
}
let trxCount = this.getFromStore("transactionCount");
trxCount--;
// if transactions inception move one step back and
// wait until all the transactions have been completed
if (trxCount) {
this.store("transactionCount", trxCount);
return;
}
this._clearTransaction();
try {
// commit the transaction
await trx.commit();
} catch (err) {
await trx.rollback();
throw new Error(
`Could not Commit Transaction: ${err.message}`
);
}
}
/* Rollback existing transaction */
async rollbackTransaction() {
this._dbInitialized();
const trx = this.getFromStore("trx");
if (!trx) {
throw new Error(
"Could not find transaction to rollback"
);
}
this._clearTransaction();
try {
await trx.rollback();
} catch (err) {
throw new Error(
`Error while rolling back transaction ${err}`
);
}
}
...
}
// singleton
module.exports = new ContextHandler();We finally have the methods required to start, commit or rollback a transaction. The transaction object is itself stored in the context store. However, how will the knex instance be able to access this transaction? We will try to overwrite the original knex instance with a proxy. This proxy will trace calls to the database such as:
- knex.raw()
- knex.select().from(table)
- knex(table).select(‘’) and replace them with the expression that we used before: (trx||knex) (if there is a transaction in the local storage, use this one instead of the knex instance)
class ContextHandler {
...
/* Wraps the db instance and returns its wrapped */
wrapDB(db) {
// proxy db
const contextHandler = this;
db = new Proxy(db, {
// for when called like db(TABLE_NAME).select()...
apply: function (target, _, argumentsList) {
const trx = contextHandler.getTransaction();
// in case a transaction is already open
// execute psql code in its scope
return (trx || target)(...argumentsList);
},
// when called like db.select().from(TABLE_NAME)...
// or db.raw() statements
get: function (target, prop) {
// dbMethods is a string list of all the
// knex methods which can be executed in
// a transaction
// ('select', 'from', 'raw', etc)
if (dbMethods.includes(prop)) {
const trx = contextHandler
.getTransaction();
if (trx) {
return function (...args) {
return target[prop](
...args
).transacting(trx);
}.bind(target);
}
}
return target[prop];
}
});
this.db = db;
return db;
}
/* returns the database object */
getDb() {
return this.db;
}
}
// singleton
module.exports = new ContextHandler();Now that the Context Handler module is finally written we can include it into the rest of our architeture by following this simple steps:
- Add it as a middleware to our express server.
- Alter the original knex object through it
// wherever it might be located
const express require('express');
const knex = require('knex')({client: 'pg'});
const ch = require('./context_handler');
const app = express();
// register the context handler middleware
app.use(ch.getMiddleware());
ch.wrapDB(knex)
...
app.get('/test', async (req, res) => {
try {
await ch.startTransaction();
const result = await dbFunction1();
await dbFunction2(result.id);
await ch.endTransaction();
} catch (err) {
await ch.rollbackTransaction();
}
})
...
dbFunction1() {
// will be executed inside transaction
return ch
.getDb()
.select()
.from('mytable')
.first();
}
dbFunction2(id) {
// this one as well
return ch
.getDb()('mytable')
.update({ foo: 'test' })
.where({ id });
}Caveat
Obviously this work does not come with limitations. Since the context storage is common across Async Resources with the same parent ids trying to create different transactions (concurrently) into children scopes will inadvertently cause transaction overwrites. For example:
async function executeTransaction() {
await ch.startTransaction();
... do stuff ...
await ch.endTransaction();
}
app.get('/test', async (req, res) => {
try {
await Promise.all([
executeTransaction(),
executeTransaction(),
executeTransaction()
])
} catch (err) {
await ch.rollbackTransaction();
}
})Since all of the executeTransaction functions where called in the same scope then they will share the same context storage. This means that whenever each startTransaction is called then it will try to add a trx object in memory (practically increasing the trx counter). Consequently, even though the code seems to be using different transactions, it will just be utilizing one of them. I will try to create a post on how to fix this issue and be able to initiate multiple transactions concurrently on the same context. However until then you may use this software (or ideas derived from it) to execute sequential transactions.